2024

Buffalo: Biomedical Vision-Language Understanding with Cross-Modal Prototype and Federated Foundation Model Collaboration
Bingjie YAN, Qian CHEN, Yiqiang CHEN†, Xinlong JIANG, Wuliang HUANG, Bingyu WANG, Zhirui WANG, Chenlong GAO, Teng ZHANG († corresponding author )
ACM CIKM'24, CCF-B, CORE-A (Acceptance Rate: 22.7%) (2024) Oral
Federated learning (FL) enables collaborative learning across multiple biomedical data silos with multimodal foundation models while preserving privacy. Due to the heterogeneity in data processing and collection methodologies across diverse medical institutions and the varying medical inspections patients undergo, modal heterogeneity exists in practical scenarios, where severe modal heterogeneity may even prevent model training. With privacy considerations, data transfer cannot be permitted, restricting knowledge exchange among different clients. To trickle these issues, we propose a cross-modal prototype imputation method for visual-language understanding (Buffalo) with only a slight increase in communication cost, which can improve the performance of fine-tuning general foundation models for downstream biomedical tasks. We conducted extensive experiments on medical report generation and biomedical visual question-answering tasks. The results demonstrate that Buffalo can fully utilize data from all clients to improve model generalization compared to other modal imputation methods in three modal heterogeneity scenarios, approaching or even surpassing the performance in the ideal scenario without missing modality.
Buffalo: Biomedical Vision-Language Understanding with Cross-Modal Prototype and Federated Foundation Model Collaboration
Bingjie YAN, Qian CHEN, Yiqiang CHEN†, Xinlong JIANG, Wuliang HUANG, Bingyu WANG, Zhirui WANG, Chenlong GAO, Teng ZHANG († corresponding author )
ACM CIKM'24, CCF-B, CORE-A (Acceptance Rate: 22.7%) (2024) Oral
Federated learning (FL) enables collaborative learning across multiple biomedical data silos with multimodal foundation models while preserving privacy. Due to the heterogeneity in data processing and collection methodologies across diverse medical institutions and the varying medical inspections patients undergo, modal heterogeneity exists in practical scenarios, where severe modal heterogeneity may even prevent model training. With privacy considerations, data transfer cannot be permitted, restricting knowledge exchange among different clients. To trickle these issues, we propose a cross-modal prototype imputation method for visual-language understanding (Buffalo) with only a slight increase in communication cost, which can improve the performance of fine-tuning general foundation models for downstream biomedical tasks. We conducted extensive experiments on medical report generation and biomedical visual question-answering tasks. The results demonstrate that Buffalo can fully utilize data from all clients to improve model generalization compared to other modal imputation methods in three modal heterogeneity scenarios, approaching or even surpassing the performance in the ideal scenario without missing modality.
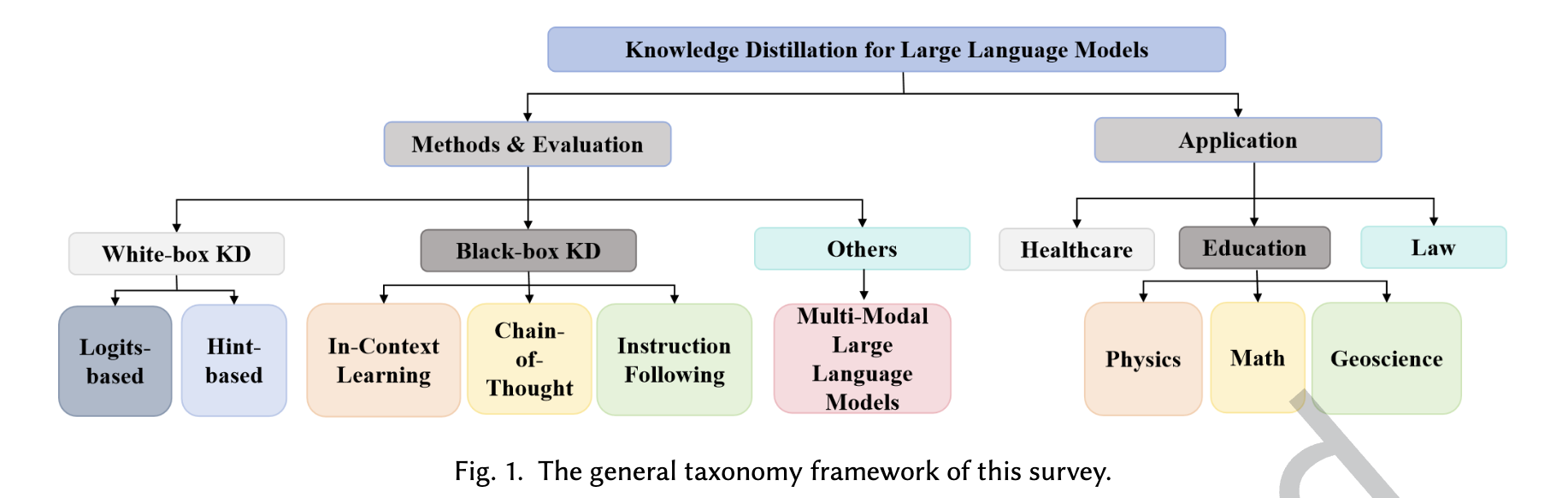
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application
Chuanpeng YANG, Wang LU†, Yao ZHU, Yidong WANG, Qian CHEN, Chenlong GAO, Bingjie YAN, Yiqiang CHEN († corresponding author )
Transactions on Intelligent Systems and Technology (TIST), JCR-Q1, IF=7.2 (2024)
Large Language Models (LLMs) have showcased exceptional capabilities in various domains, attracting significant interest from both academia and industry. Despite their impressive performance, the substantial size and computational demands of LLMs pose considerable challenges for practical deployment, particularly in environments with limited resources. The endeavor to compress language models while maintaining their accuracy has become a focal point of research. Among the various methods, knowledge distillation has emerged as an effective technique to enhance inference speed without greatly compromising performance. This paper presents a thorough survey from three aspects: method, evaluation, and application, exploring knowledge distillation techniques tailored specifically for LLMs. Specifically, we divide the methods into white-box KD and black-box KD to better illustrate their differences. Furthermore, we also explored the evaluation tasks and distillation effects between different distillation methods, and proposed directions for future research. Through in-depth understanding of the latest advancements and practical applications, this survey provides valuable resources for researchers, paving the way for sustained progress in this field.
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application
Chuanpeng YANG, Wang LU†, Yao ZHU, Yidong WANG, Qian CHEN, Chenlong GAO, Bingjie YAN, Yiqiang CHEN († corresponding author )
Transactions on Intelligent Systems and Technology (TIST), JCR-Q1, IF=7.2 (2024)
Large Language Models (LLMs) have showcased exceptional capabilities in various domains, attracting significant interest from both academia and industry. Despite their impressive performance, the substantial size and computational demands of LLMs pose considerable challenges for practical deployment, particularly in environments with limited resources. The endeavor to compress language models while maintaining their accuracy has become a focal point of research. Among the various methods, knowledge distillation has emerged as an effective technique to enhance inference speed without greatly compromising performance. This paper presents a thorough survey from three aspects: method, evaluation, and application, exploring knowledge distillation techniques tailored specifically for LLMs. Specifically, we divide the methods into white-box KD and black-box KD to better illustrate their differences. Furthermore, we also explored the evaluation tasks and distillation effects between different distillation methods, and proposed directions for future research. Through in-depth understanding of the latest advancements and practical applications, this survey provides valuable resources for researchers, paving the way for sustained progress in this field.
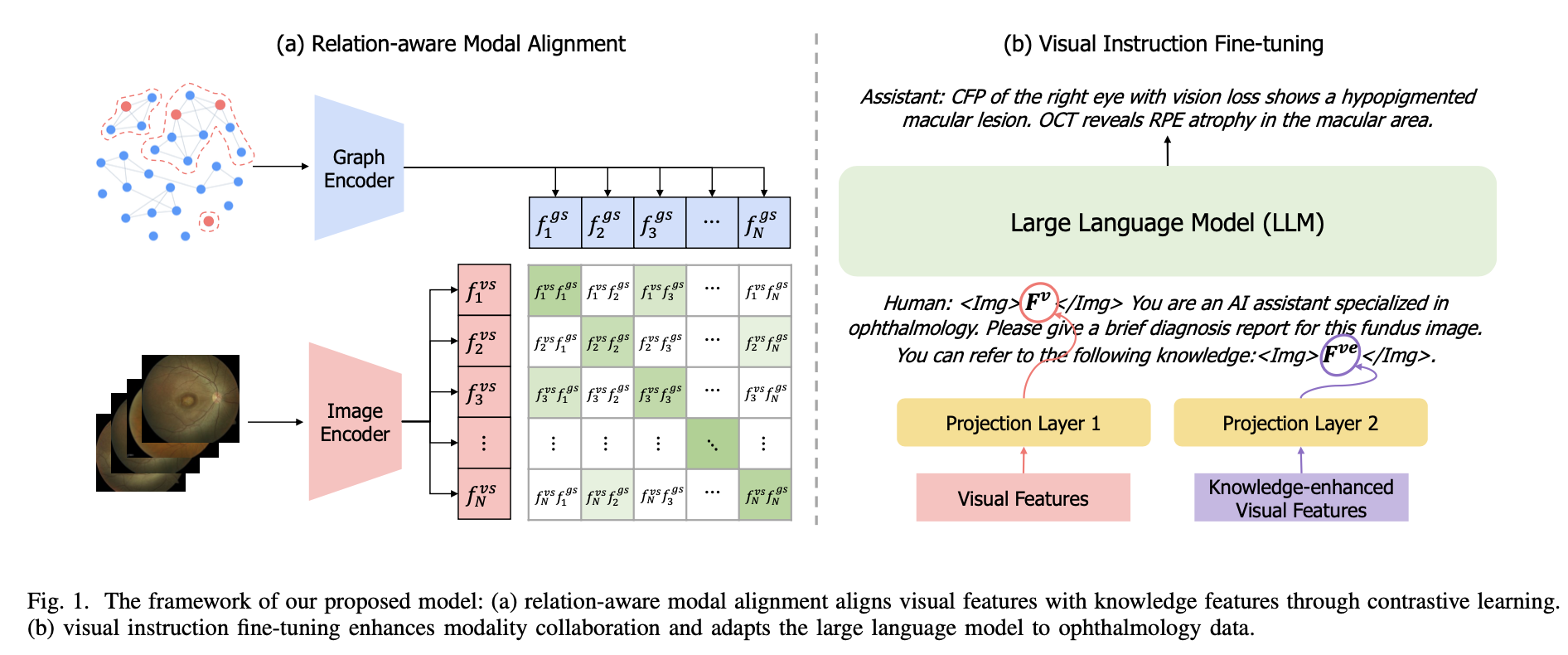
EyeGraphGPT: Knowledge Graph Enhanced Multimodal Large Language Model for Ophthalmic Report Generation
Zhirui WANG, Xinlong JIANG†, Chenlong GAO, Fan DONG, Weiwei DAI, Bingyu WANG, Bingjie YAN, Qian CHEN, Wuliang HUANG, Teng ZHANG, Yiqiang CHEN († corresponding author )
IEEE BIBM'24, CCF-B (2024) Just accepted. Oral
Automatic generation of ophthalmic reports holds significant potential to lessen clinicians’ workload, enhance work efficiency, and alleviate the imbalance between clinicians and patients. Recent advancements in multimodal large language models, represented by GPT-4, have demonstrated remarkable performance in the general domain. However, training such models necessitates a substantial amount of paired image-text data, yet paired ophthalmic data is limited, and ophthalmic reports are laden with specialized terminologies, making it challenging to transfer the training paradigm to the ophthalmic domain. In this paper, we propose EyeGraphGPT, a knowledge graph enhanced multimodal large language model for ophthalmic report generation. Specifically, we construct a knowledge graph by leveraging the knowledge from a medical database and expertise from ophthalmic experts to model relationships among ophthalmic diseases, enhancing the model’s focus on key disease information. We then perform relation-aware modal alignment to incorporate knowledge graph features into visual features, and further enhance modality collaboration through visual instruction fine-tuning to adapt the model to the ophthalmic domain. Our experiments on a real-world dataset demonstrates that EyeGraphGPT outperforms previous state-of-the-art models, highlighting its superiority in scenarios with limited medical data and extensive specialized terminologies.
EyeGraphGPT: Knowledge Graph Enhanced Multimodal Large Language Model for Ophthalmic Report Generation
Zhirui WANG, Xinlong JIANG†, Chenlong GAO, Fan DONG, Weiwei DAI, Bingyu WANG, Bingjie YAN, Qian CHEN, Wuliang HUANG, Teng ZHANG, Yiqiang CHEN († corresponding author )
IEEE BIBM'24, CCF-B (2024) Just accepted. Oral
Automatic generation of ophthalmic reports holds significant potential to lessen clinicians’ workload, enhance work efficiency, and alleviate the imbalance between clinicians and patients. Recent advancements in multimodal large language models, represented by GPT-4, have demonstrated remarkable performance in the general domain. However, training such models necessitates a substantial amount of paired image-text data, yet paired ophthalmic data is limited, and ophthalmic reports are laden with specialized terminologies, making it challenging to transfer the training paradigm to the ophthalmic domain. In this paper, we propose EyeGraphGPT, a knowledge graph enhanced multimodal large language model for ophthalmic report generation. Specifically, we construct a knowledge graph by leveraging the knowledge from a medical database and expertise from ophthalmic experts to model relationships among ophthalmic diseases, enhancing the model’s focus on key disease information. We then perform relation-aware modal alignment to incorporate knowledge graph features into visual features, and further enhance modality collaboration through visual instruction fine-tuning to adapt the model to the ophthalmic domain. Our experiments on a real-world dataset demonstrates that EyeGraphGPT outperforms previous state-of-the-art models, highlighting its superiority in scenarios with limited medical data and extensive specialized terminologies.
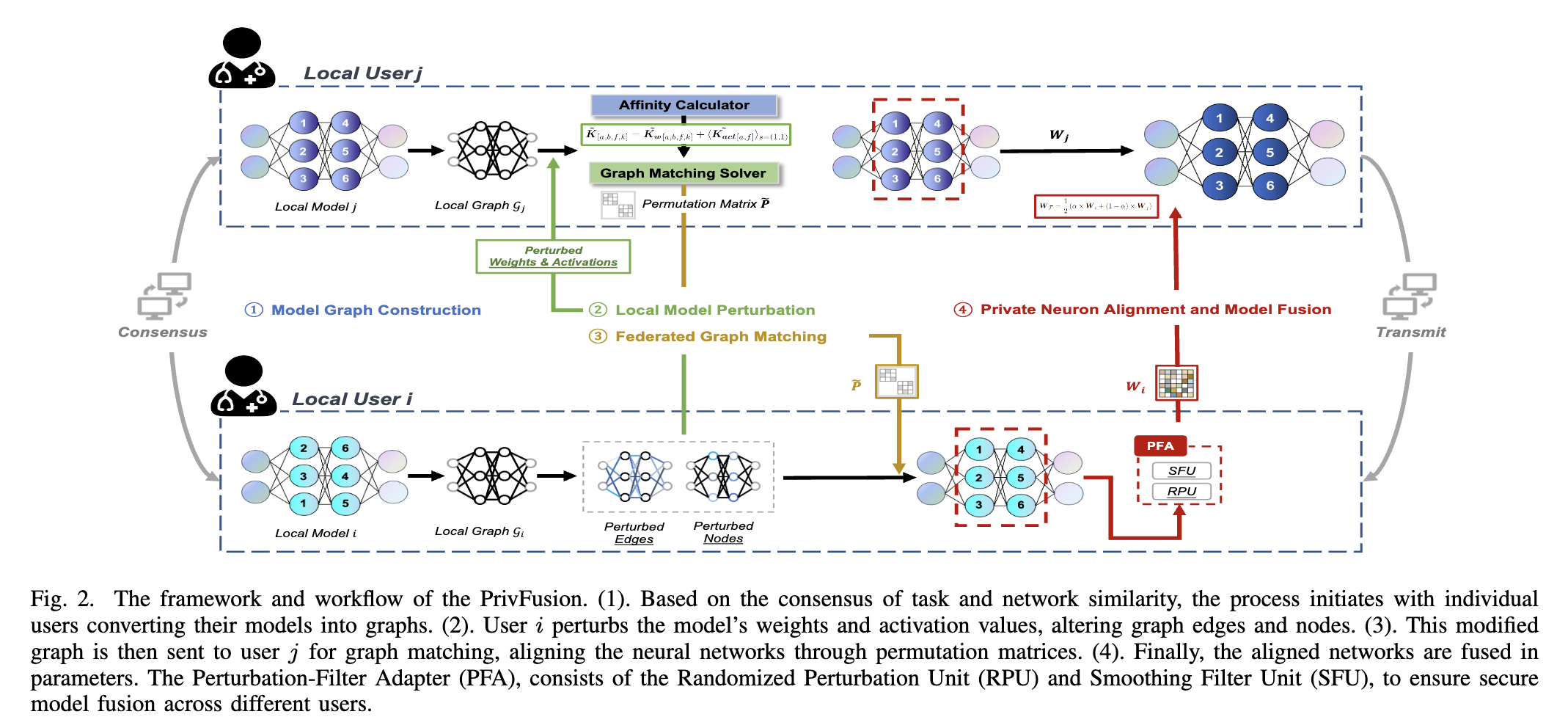
PrivFusion: Privacy-Preserving Model Fusion via Decentralized Federated Graph Matching
Qian CHEN, Yiqiang CHEN†, Xinlong JIANG, Weiwei DAI, Wuliang HUANG, Bingjie YAN, Zhen YAN, Lu WANG, Bo YE († corresponding author )
IEEE Transactions on Knowledge and Data Engineering (TKDE), CCF-A, CORE-A* (2024)
Model fusion is becoming a crucial component in the context of model-as-a-service scenarios, enabling the delivery of high-quality model services to local users. However, this approach introduces privacy risks and imposes certain limitations on its applications. Ensuring secure model exchange and knowledge fusion among users becomes a significant challenge in this setting. To tackle this issue, we propose PrivFusion, a novel architecture that preserves privacy while facilitating model fusion under the constraints of local differential privacy. PrivFusion leverages a graph-based structure, enabling the fusion of models from multiple parties without additional training. By employing randomized mechanisms, PrivFusion ensures privacy guarantees throughout the fusion process. To enhance model privacy, our approach incorporates a hybrid local differentially private mechanism and decentralized federated graph matching, effectively protecting both activation values and weights. Additionally, we introduce a perturbation filter adapter to alleviate the impact of randomized noise, thereby recovering the utility of the fused model. Through extensive experiments conducted on diverse image datasets and real-world healthcare applications, we provide empirical evidence showcasing the effectiveness of PrivFusion in maintaining model performance while preserving privacy. Our contributions offer valuable insights and practical solutions for secure and collaborative data analysis within the domain of privacy-preserving model fusion.
PrivFusion: Privacy-Preserving Model Fusion via Decentralized Federated Graph Matching
Qian CHEN, Yiqiang CHEN†, Xinlong JIANG, Weiwei DAI, Wuliang HUANG, Bingjie YAN, Zhen YAN, Lu WANG, Bo YE († corresponding author )
IEEE Transactions on Knowledge and Data Engineering (TKDE), CCF-A, CORE-A* (2024)
Model fusion is becoming a crucial component in the context of model-as-a-service scenarios, enabling the delivery of high-quality model services to local users. However, this approach introduces privacy risks and imposes certain limitations on its applications. Ensuring secure model exchange and knowledge fusion among users becomes a significant challenge in this setting. To tackle this issue, we propose PrivFusion, a novel architecture that preserves privacy while facilitating model fusion under the constraints of local differential privacy. PrivFusion leverages a graph-based structure, enabling the fusion of models from multiple parties without additional training. By employing randomized mechanisms, PrivFusion ensures privacy guarantees throughout the fusion process. To enhance model privacy, our approach incorporates a hybrid local differentially private mechanism and decentralized federated graph matching, effectively protecting both activation values and weights. Additionally, we introduce a perturbation filter adapter to alleviate the impact of randomized noise, thereby recovering the utility of the fused model. Through extensive experiments conducted on diverse image datasets and real-world healthcare applications, we provide empirical evidence showcasing the effectiveness of PrivFusion in maintaining model performance while preserving privacy. Our contributions offer valuable insights and practical solutions for secure and collaborative data analysis within the domain of privacy-preserving model fusion.
Im2col-Winograd: An Efficient and Flexible Fused-Winograd Convolution for NHWC Format on GPUs
Zhiyi ZHANG, Pengfei ZHANG, Zhuopin XU, Bingjie YAN, Qi WANG† († corresponding author )
ICPP'24, CCF-B (2024) Oral
Compared to standard convolution, Winograd algorithm has lower time complexity and can accelerate the execution of convolutional neural networks. Previous studies have utilized Winograd to implement 2D convolution on GPUs, mainly using 2D Winograd, and arranging tensors in NCHW or CHWN format instead of NHWC to make data access coalesced. Due to the higher space complexity of Winograd and limited hardware resources, these implementations are usually confined to small filters. To provide an efficient and flexible fused-Winograd convolution for NHWC format on GPUs, we propose Im2col-Winograd. This algorithm decomposes an ND convolution into a series of 1D convolutions to utilize 1D Winograd, thereby reducing space complexity and data-access discontinuity. The reduced space complexity makes Im2col-Winograd less restricted by hardware capability, enabling it to accommodate a wider range of filter shapes. Our implementations support 2-9 filter widths and do not use any workspace to store intermediate variables. According to the experiments, Im2col-Winograd achieves a speedup of 0.788 × to 2.05 × over the fastest benchmark algorithm in cuDNN; and shows similar convergence to PyTorch on Cifar10 and ILSVRC2012 datasets. Along with memory efficiency, the more generalized acceleration offered by Im2col-Winograd can be beneficial for extracting features at different convolution scales.
Im2col-Winograd: An Efficient and Flexible Fused-Winograd Convolution for NHWC Format on GPUs
Zhiyi ZHANG, Pengfei ZHANG, Zhuopin XU, Bingjie YAN, Qi WANG† († corresponding author )
ICPP'24, CCF-B (2024) Oral
Compared to standard convolution, Winograd algorithm has lower time complexity and can accelerate the execution of convolutional neural networks. Previous studies have utilized Winograd to implement 2D convolution on GPUs, mainly using 2D Winograd, and arranging tensors in NCHW or CHWN format instead of NHWC to make data access coalesced. Due to the higher space complexity of Winograd and limited hardware resources, these implementations are usually confined to small filters. To provide an efficient and flexible fused-Winograd convolution for NHWC format on GPUs, we propose Im2col-Winograd. This algorithm decomposes an ND convolution into a series of 1D convolutions to utilize 1D Winograd, thereby reducing space complexity and data-access discontinuity. The reduced space complexity makes Im2col-Winograd less restricted by hardware capability, enabling it to accommodate a wider range of filter shapes. Our implementations support 2-9 filter widths and do not use any workspace to store intermediate variables. According to the experiments, Im2col-Winograd achieves a speedup of 0.788 × to 2.05 × over the fastest benchmark algorithm in cuDNN; and shows similar convergence to PyTorch on Cifar10 and ILSVRC2012 datasets. Along with memory efficiency, the more generalized acceleration offered by Im2col-Winograd can be beneficial for extracting features at different convolution scales.
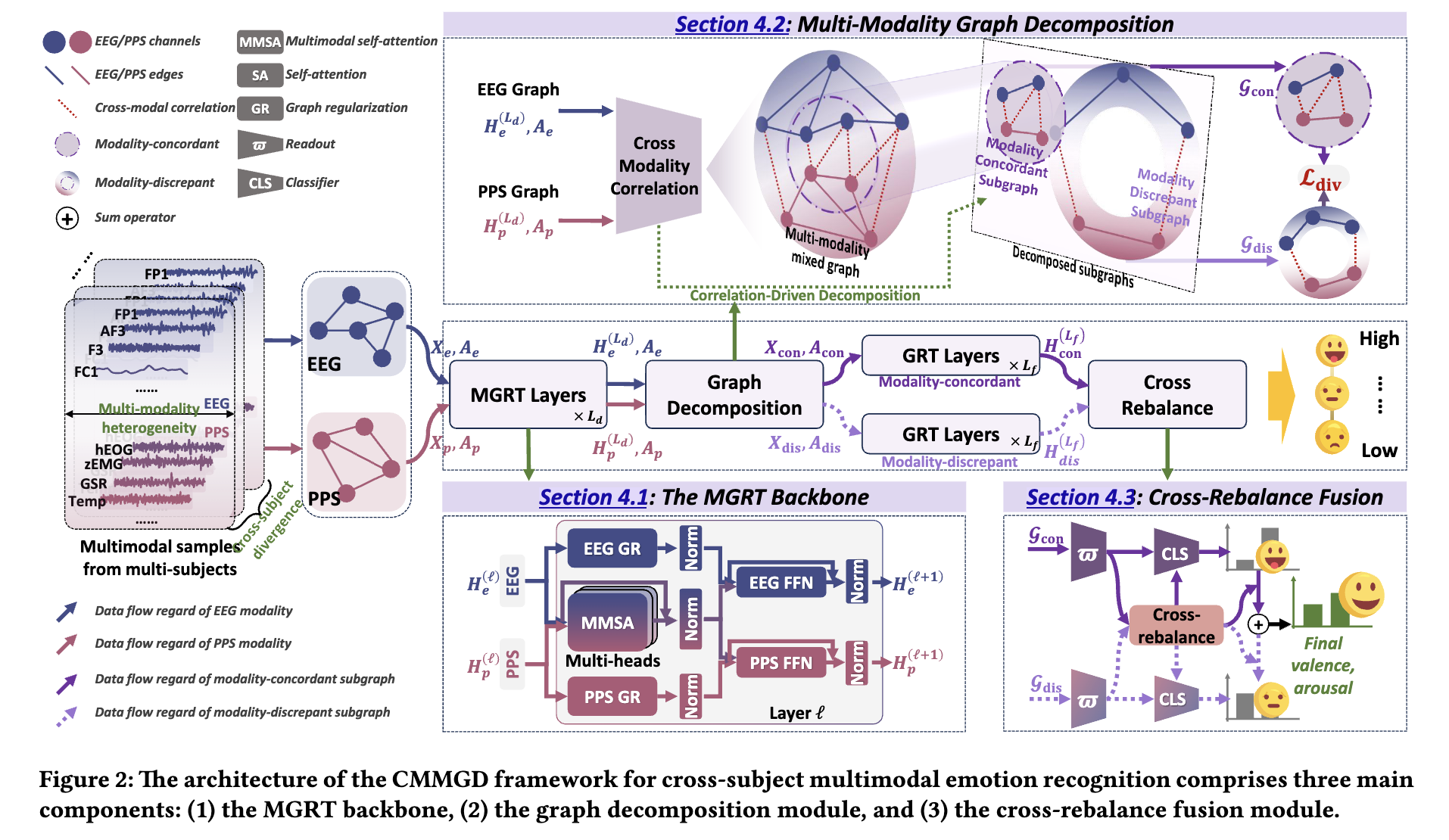
Correlation-Driven Multi-Modality Graph Decomposition for Cross-Subject Emotion Recognition
Wuliang HUANG, Yiqiang CHEN†, Xinlong JIANG, Chenlong GAO, Qian CHEN, Teng ZHANG, Bingjie YAN, Yifan WANG, Jianrong YANG († corresponding author )
ACM MM'24, CCF-A, CORE-A* (2024) Poster
Multi-modality physiological signal-based emotion recognition has attracted increasing attention as its capacity to capture human affective states comprehensively. Due to multi-modality heterogeneity and cross-subject divergence, practical applications struggle with generalizing models across individuals. Effectively addressing both issues requires mitigating the gap between multi-modality signals while acquiring generalizable representations across subjects. However, existing approaches often handle these dual challenges separately, resulting in suboptimal generalization. This study introduces a novel framework, termed Correlation-Driven Multi-Modality Graph Decomposition (CMMGD). The proposed CMMGD initially captures adaptive cross-modal correlations to connect each unimodal graph to a multi-modality mixed graph. To simultaneously address the dual challenges, it incorporates a correlation-driven graph decomposition module that decomposes the mixed graph into concordant and discrepant subgraphs based on the correlations. The decomposed concordant subgraph encompasses consistently activated features across modalities and subjects during emotion elicitation, unveiling a generalizable subspace. Additionally, we design a Multi-Modality Graph Regularized Transformer (MGRT) backbone specifically tailored for multimodal physiological signals. The MGRT can alleviate the over-smoothing issue and mitigate over-reliance on any single modality. Extensive experiments demonstrate that CMMGD outperforms the state-of-the-art methods by 1.79% and 2.65% on DEAP and MAHNOB-HCI datasets, respectively, under the leave-one-subject-out cross-validation strategy.
Correlation-Driven Multi-Modality Graph Decomposition for Cross-Subject Emotion Recognition
Wuliang HUANG, Yiqiang CHEN†, Xinlong JIANG, Chenlong GAO, Qian CHEN, Teng ZHANG, Bingjie YAN, Yifan WANG, Jianrong YANG († corresponding author )
ACM MM'24, CCF-A, CORE-A* (2024) Poster
Multi-modality physiological signal-based emotion recognition has attracted increasing attention as its capacity to capture human affective states comprehensively. Due to multi-modality heterogeneity and cross-subject divergence, practical applications struggle with generalizing models across individuals. Effectively addressing both issues requires mitigating the gap between multi-modality signals while acquiring generalizable representations across subjects. However, existing approaches often handle these dual challenges separately, resulting in suboptimal generalization. This study introduces a novel framework, termed Correlation-Driven Multi-Modality Graph Decomposition (CMMGD). The proposed CMMGD initially captures adaptive cross-modal correlations to connect each unimodal graph to a multi-modality mixed graph. To simultaneously address the dual challenges, it incorporates a correlation-driven graph decomposition module that decomposes the mixed graph into concordant and discrepant subgraphs based on the correlations. The decomposed concordant subgraph encompasses consistently activated features across modalities and subjects during emotion elicitation, unveiling a generalizable subspace. Additionally, we design a Multi-Modality Graph Regularized Transformer (MGRT) backbone specifically tailored for multimodal physiological signals. The MGRT can alleviate the over-smoothing issue and mitigate over-reliance on any single modality. Extensive experiments demonstrate that CMMGD outperforms the state-of-the-art methods by 1.79% and 2.65% on DEAP and MAHNOB-HCI datasets, respectively, under the leave-one-subject-out cross-validation strategy.

Model Trip: Enhancing Privacy and Fairness in Model Fusion across Multi-Federations for Trustworthy Global Healthcare
Qian CHEN, Yiqiang CHEN†, Bingjie YAN, Xinlong JIANG, Xiaojin ZHANG, Yan KANG, Teng ZHANG, Wuliang HUANG, Chenlong GAO, Lixin FAN, Qiang YANG († corresponding author )
ICDE'24, CCF-A (2024) Oral
Federated Learning has emerged as a revolutionary innovation in the evolving landscape of global healthcare, fostering collaboration among institutions and facilitating collaborative data analysis. As practical applications continue to proliferate, numerous federations have formed in different regions. The optimization and sustainable development of federation-pretrained models have emerged as new challenges. These challenges primarily encompass privacy, population shift and data dependency, which may lead to severe consequences such as the leakage of sensitive information within models and training samples, unfair model performance and resource burdens. To tackle these issues, we propose FairFusion, a cross-federation model fusion approach that enhances privacy and fairness. FairFusion operates across federations within a Model Trip paradigm, integrating knowledge from diverse federations to continually enhance model performance. Through federated model fusion, multi-objective quantification and optimization, FairFusion obtains trustworthy solutions that excel in utility, privacy and fairness. We conduct comprehensive experiments on three public real-world healthcare datasets. The results demonstrate that FairFusion achieves outstanding model fusion performance in terms of utility and fairness across various model structures and subgroups with sensitive attributes while guaranteeing model privacy.
Model Trip: Enhancing Privacy and Fairness in Model Fusion across Multi-Federations for Trustworthy Global Healthcare
Qian CHEN, Yiqiang CHEN†, Bingjie YAN, Xinlong JIANG, Xiaojin ZHANG, Yan KANG, Teng ZHANG, Wuliang HUANG, Chenlong GAO, Lixin FAN, Qiang YANG († corresponding author )
ICDE'24, CCF-A (2024) Oral
Federated Learning has emerged as a revolutionary innovation in the evolving landscape of global healthcare, fostering collaboration among institutions and facilitating collaborative data analysis. As practical applications continue to proliferate, numerous federations have formed in different regions. The optimization and sustainable development of federation-pretrained models have emerged as new challenges. These challenges primarily encompass privacy, population shift and data dependency, which may lead to severe consequences such as the leakage of sensitive information within models and training samples, unfair model performance and resource burdens. To tackle these issues, we propose FairFusion, a cross-federation model fusion approach that enhances privacy and fairness. FairFusion operates across federations within a Model Trip paradigm, integrating knowledge from diverse federations to continually enhance model performance. Through federated model fusion, multi-objective quantification and optimization, FairFusion obtains trustworthy solutions that excel in utility, privacy and fairness. We conduct comprehensive experiments on three public real-world healthcare datasets. The results demonstrate that FairFusion achieves outstanding model fusion performance in terms of utility and fairness across various model structures and subgroups with sensitive attributes while guaranteeing model privacy.

FedEYE: A Scalable and Flexible End-to-end Federated Learning Platform for Ophthalmology
Bingjie YAN*, Danmin CAO*, Xinlong JIANG, Yiqiang CHEN†, Weiwei DAI†, Fan DONG, Wuliang HUANG, Teng ZHANG, Chenlong GAO, Qian CHEN, Zhen YAN, Zhirui WANG (* equal contribution, † corresponding author )
Patterns, Cell Press, JCR-Q1, IF=6.7 (2024)
Federated learning (FL) enables training machine learning models on decentralized medical data while preserving privacy. Despite growing research on FL algorithms and systems, building real-world FL applications requires extensive expertise, posing barriers for medical researchers. FedEYE, an end-to-end FL platform tailored for ophthalmologists without programming skills, is developed here to easily create federated projects on tasks like image classification. The platform provides rich capabilities, scalability, flexible deployment, and separation of concerns. With user-friendly interfaces and comprehension of underlying mechanisms, FedEYE strives to democratize FL for ophthalmology.
FedEYE: A Scalable and Flexible End-to-end Federated Learning Platform for Ophthalmology
Bingjie YAN*, Danmin CAO*, Xinlong JIANG, Yiqiang CHEN†, Weiwei DAI†, Fan DONG, Wuliang HUANG, Teng ZHANG, Chenlong GAO, Qian CHEN, Zhen YAN, Zhirui WANG (* equal contribution, † corresponding author )
Patterns, Cell Press, JCR-Q1, IF=6.7 (2024)
Federated learning (FL) enables training machine learning models on decentralized medical data while preserving privacy. Despite growing research on FL algorithms and systems, building real-world FL applications requires extensive expertise, posing barriers for medical researchers. FedEYE, an end-to-end FL platform tailored for ophthalmologists without programming skills, is developed here to easily create federated projects on tasks like image classification. The platform provides rich capabilities, scalability, flexible deployment, and separation of concerns. With user-friendly interfaces and comprehension of underlying mechanisms, FedEYE strives to democratize FL for ophthalmology.
2023
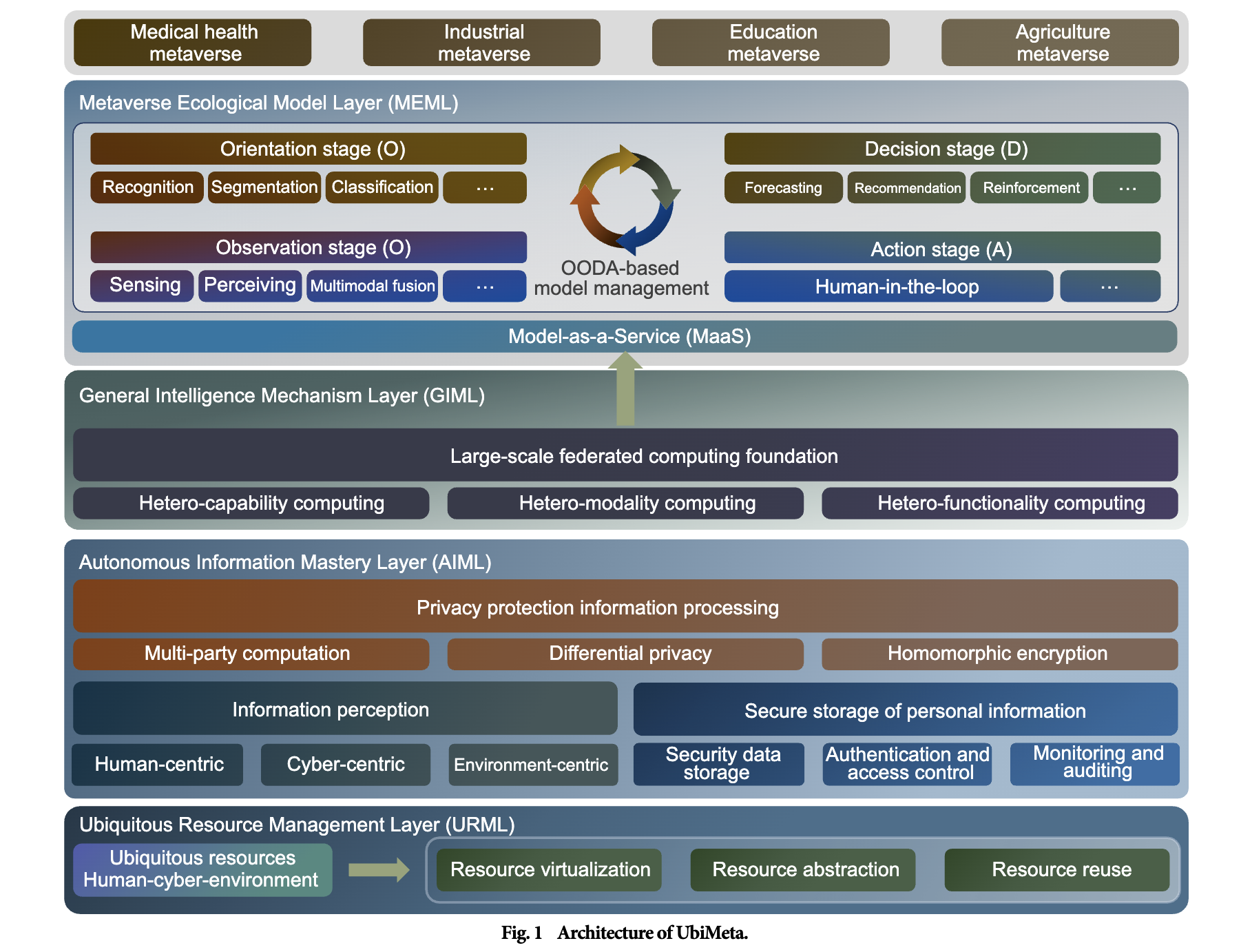
UbiMeta: A Ubiquitous Operating System Model for Metaverse
Yiqiang CHEN†, Wuliang HUANG, Xinlong JIANG, Teng ZHANG, Yi WANG, Bingjie YAN, Zhirui WANG, Qian CHEN, Yunbing XING, Dong LI, Guodong LONG († corresponding author )
International Journal of Crowd Science (IJCS), (2023)
The metaverse signifies the amalgamation of virtual and tangible realms through human-computer interaction. The seamless integration of human, cyber, and environments within ubiquitous computing plays a pivotal role in fully harnessing the metaverse's capabilities. Nevertheless, metaverse operating systems face substantial hurdles in terms of accessing ubiquitous resources, processing information while safeguarding privacy and security, and furnishing artificial intelligence capabilities to downstream applications. To tackle these challenges, this paper introduces the UbiMeta model, a specialized ubiquitous operating system designed specifically for the metaverse. It extends the capabilities of traditional ubiquitous operating systems and focuses on adapting downstream models and operational capacity to effectively function within the metaverse. UbiMeta comprises four layers: the Ubiquitous Resource Management Layer (URML), the Autonomous Information Mastery Layer (AIML), the General Intelligence Mechanism Layer (GIML), and the Metaverse Ecological Model Layer (MEML). The URML facilitates the seamless incorporation and management of various external devices and resources. It provides a framework for integrating and controlling these resources, including virtualization, abstraction, and reuse. The AIML is responsible for perceiving information and safeguarding privacy and security during storage and processing. The GIML leverages large-scale pre-trained deep-learning feature extractors to obtain effective features for processing information. The MEML focuses on constructing metaverse applications using the principles of Model-as-a-Service (MaaS) and the OODA loop (Observation, Orientation, Decision, Action). It leverages the vast amount of information collected by the URML and AIML layers to build a robust metaverse ecosystem. Furthermore, this study explores how UbiMeta enhances user experiences and fosters innovation in various metaverse domains. It highlights the potential of UbiMeta in revolutionizing medical healthcare, industrial practices, education, and agriculture within the metaverse.
UbiMeta: A Ubiquitous Operating System Model for Metaverse
Yiqiang CHEN†, Wuliang HUANG, Xinlong JIANG, Teng ZHANG, Yi WANG, Bingjie YAN, Zhirui WANG, Qian CHEN, Yunbing XING, Dong LI, Guodong LONG († corresponding author )
International Journal of Crowd Science (IJCS), (2023)
The metaverse signifies the amalgamation of virtual and tangible realms through human-computer interaction. The seamless integration of human, cyber, and environments within ubiquitous computing plays a pivotal role in fully harnessing the metaverse's capabilities. Nevertheless, metaverse operating systems face substantial hurdles in terms of accessing ubiquitous resources, processing information while safeguarding privacy and security, and furnishing artificial intelligence capabilities to downstream applications. To tackle these challenges, this paper introduces the UbiMeta model, a specialized ubiquitous operating system designed specifically for the metaverse. It extends the capabilities of traditional ubiquitous operating systems and focuses on adapting downstream models and operational capacity to effectively function within the metaverse. UbiMeta comprises four layers: the Ubiquitous Resource Management Layer (URML), the Autonomous Information Mastery Layer (AIML), the General Intelligence Mechanism Layer (GIML), and the Metaverse Ecological Model Layer (MEML). The URML facilitates the seamless incorporation and management of various external devices and resources. It provides a framework for integrating and controlling these resources, including virtualization, abstraction, and reuse. The AIML is responsible for perceiving information and safeguarding privacy and security during storage and processing. The GIML leverages large-scale pre-trained deep-learning feature extractors to obtain effective features for processing information. The MEML focuses on constructing metaverse applications using the principles of Model-as-a-Service (MaaS) and the OODA loop (Observation, Orientation, Decision, Action). It leverages the vast amount of information collected by the URML and AIML layers to build a robust metaverse ecosystem. Furthermore, this study explores how UbiMeta enhances user experiences and fosters innovation in various metaverse domains. It highlights the potential of UbiMeta in revolutionizing medical healthcare, industrial practices, education, and agriculture within the metaverse.
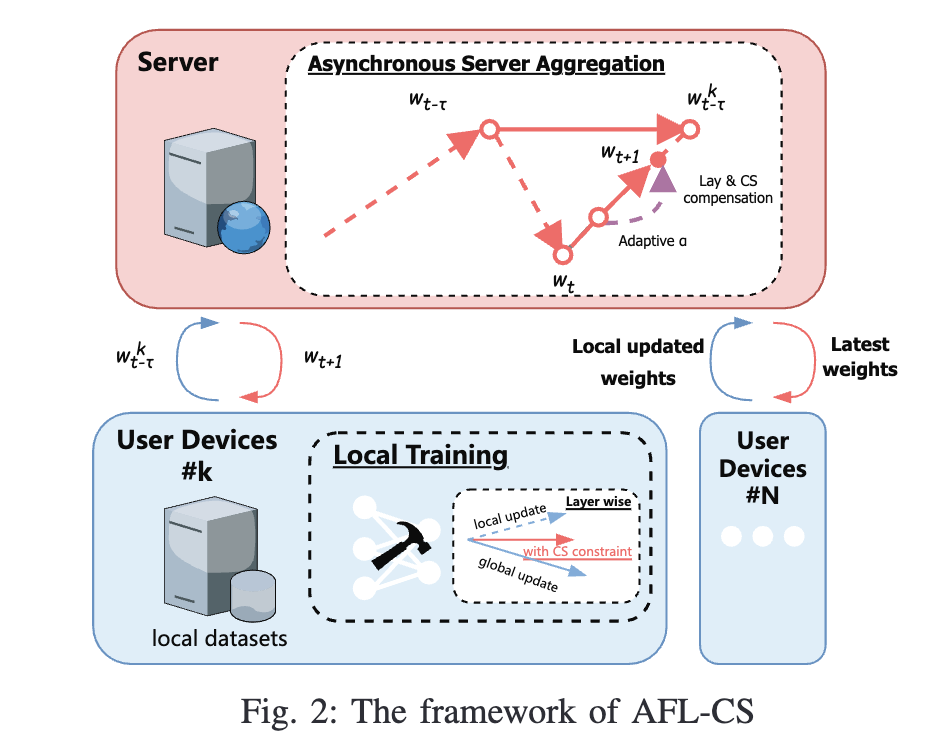
AFL-CS: Asynchronous Federated Learning with Cosine Similarity-based Penalty Term and Aggregation
Bingjie YAN, Xinlong JIANG†, Yiqiang CHEN†, Chenlong GAO, Xuequn LIU († corresponding author )
IEEE ICPADS, CCF-C (2023) Oral
Horizontal Federated Learning offers a means to develop machine learning models in the realm of medical application while preserving the confidentiality and security of patient data. However, due to the substantial heterogeneity of the devices in medical institution, traditional synchronous federated aggregation methods result in a noticeable decrease in training efficiency, thereby impacting the application and deployment of federated learning. Asynchronous Federated Learning (AFL) model aggregation methods can mitigate this problem but present new challenges in terms of convergence stability and speed. In this paper, we propose a cosine similarity-based layer-wise penalty term and asynchronous model aggregation method AFL-CS, which considers the global model convergence direction during local training. Compared with existing AFL aggregation methods, AFL-CS can achieve faster and more consistent convergence direction to superior performance especially in non-iid settings with high statistical heterogeneity, even reaching and exceeding synchronous FL.
AFL-CS: Asynchronous Federated Learning with Cosine Similarity-based Penalty Term and Aggregation
Bingjie YAN, Xinlong JIANG†, Yiqiang CHEN†, Chenlong GAO, Xuequn LIU († corresponding author )
IEEE ICPADS, CCF-C (2023) Oral
Horizontal Federated Learning offers a means to develop machine learning models in the realm of medical application while preserving the confidentiality and security of patient data. However, due to the substantial heterogeneity of the devices in medical institution, traditional synchronous federated aggregation methods result in a noticeable decrease in training efficiency, thereby impacting the application and deployment of federated learning. Asynchronous Federated Learning (AFL) model aggregation methods can mitigate this problem but present new challenges in terms of convergence stability and speed. In this paper, we propose a cosine similarity-based layer-wise penalty term and asynchronous model aggregation method AFL-CS, which considers the global model convergence direction during local training. Compared with existing AFL aggregation methods, AFL-CS can achieve faster and more consistent convergence direction to superior performance especially in non-iid settings with high statistical heterogeneity, even reaching and exceeding synchronous FL.
FedTAM: Decentralized Federated Learning with a Feature Attention Based Multi-teacher Knowledge Distillation for Healthcare
Tingting MOU, Xinlong JIANG†, Jie LI, Bingjie YAN, Qian CHEN, Teng ZHANG, Wuliang HUANG, Chenlong GAO, Yiqiang CHEN († corresponding author )
IEEE ICPADS, CCF-C (2023) Oral
Federated learning has emerged as a powerful technique for training robust models while preserving data privacy and security. However, real-world applications, especially in domains like healthcare, often face challenges due to non-independent and non-identically distributed (non-iid) data across different institutions. Additionally, the heterogeneity of data and the absence of a trusted central server further hinder collaborative efforts among medical institutions. Our paper introduces a novel federated learning approach called FedTAM, which incorporates cyclic model transfer and feature attention-based multi-teacher knowledge distillation. FedTAM is designed to tailor personalized models for individual clients within a decentralized federated learning setting, where data distribution is non-iid. Notably, this method enables student clients to selectively acquire the most pertinent and valuable knowledge from teacher clients through feature attention mechanism while filtering out irrelevant information. We conduct extensive experiments across five benchmark healthcare datasets and one public image classification dataset with feature shifts. Our results conclusively demonstrate that our method achieves remarkable accuracy improvements when compared to state-of-the-art approaches. This affirms the potential of FedTAM to significantly enhance federated learning performance, especially in challenging real-world contexts like healthcare.
FedTAM: Decentralized Federated Learning with a Feature Attention Based Multi-teacher Knowledge Distillation for Healthcare
Tingting MOU, Xinlong JIANG†, Jie LI, Bingjie YAN, Qian CHEN, Teng ZHANG, Wuliang HUANG, Chenlong GAO, Yiqiang CHEN († corresponding author )
IEEE ICPADS, CCF-C (2023) Oral
Federated learning has emerged as a powerful technique for training robust models while preserving data privacy and security. However, real-world applications, especially in domains like healthcare, often face challenges due to non-independent and non-identically distributed (non-iid) data across different institutions. Additionally, the heterogeneity of data and the absence of a trusted central server further hinder collaborative efforts among medical institutions. Our paper introduces a novel federated learning approach called FedTAM, which incorporates cyclic model transfer and feature attention-based multi-teacher knowledge distillation. FedTAM is designed to tailor personalized models for individual clients within a decentralized federated learning setting, where data distribution is non-iid. Notably, this method enables student clients to selectively acquire the most pertinent and valuable knowledge from teacher clients through feature attention mechanism while filtering out irrelevant information. We conduct extensive experiments across five benchmark healthcare datasets and one public image classification dataset with feature shifts. Our results conclusively demonstrate that our method achieves remarkable accuracy improvements when compared to state-of-the-art approaches. This affirms the potential of FedTAM to significantly enhance federated learning performance, especially in challenging real-world contexts like healthcare.
2021
FedCM: A Real-time Contribution Measurement Method for Participants in Federated Learning
Bingjie YAN, Boyi LIU†, Lujia WANG, Yize ZHOU, Zhixuan LIANG, Ming LIU, Cheng-Zhong XU († corresponding author )
IJCNN, CCF-C (2021)
Federated Learning (FL) creates an ecosystem for multiple agents to collaborate on building models with data privacy consideration. The method for contribution measurement of each agent in the FL system is critical for fair credits allocation but few are proposed. In this paper, we develop a real-time contribution measurement method FedCM that is simple but powerful. The method defines the impact of each agent, comprehensively considers the current round and the previous round to obtain the contribution rate of each agent with attention aggregation. Moreover, FedCM updates contribution every round, which enable it to perform in real-time. Real-time is not considered by the existing approaches, but it is critical for FL systems to allocate computing power, communication resources, etc. Compared to the state-of-the-art method, the experimental results show that FedCM is more sensitive to data quantity and data quality under the premise of real-time. Furthermore, we developed federated learning open-source software based on FedCM. The software has been applied to identify COVID-19 based on medical images.
FedCM: A Real-time Contribution Measurement Method for Participants in Federated Learning
Bingjie YAN, Boyi LIU†, Lujia WANG, Yize ZHOU, Zhixuan LIANG, Ming LIU, Cheng-Zhong XU († corresponding author )
IJCNN, CCF-C (2021)
Federated Learning (FL) creates an ecosystem for multiple agents to collaborate on building models with data privacy consideration. The method for contribution measurement of each agent in the FL system is critical for fair credits allocation but few are proposed. In this paper, we develop a real-time contribution measurement method FedCM that is simple but powerful. The method defines the impact of each agent, comprehensively considers the current round and the previous round to obtain the contribution rate of each agent with attention aggregation. Moreover, FedCM updates contribution every round, which enable it to perform in real-time. Real-time is not considered by the existing approaches, but it is critical for FL systems to allocate computing power, communication resources, etc. Compared to the state-of-the-art method, the experimental results show that FedCM is more sensitive to data quantity and data quality under the premise of real-time. Furthermore, we developed federated learning open-source software based on FedCM. The software has been applied to identify COVID-19 based on medical images.
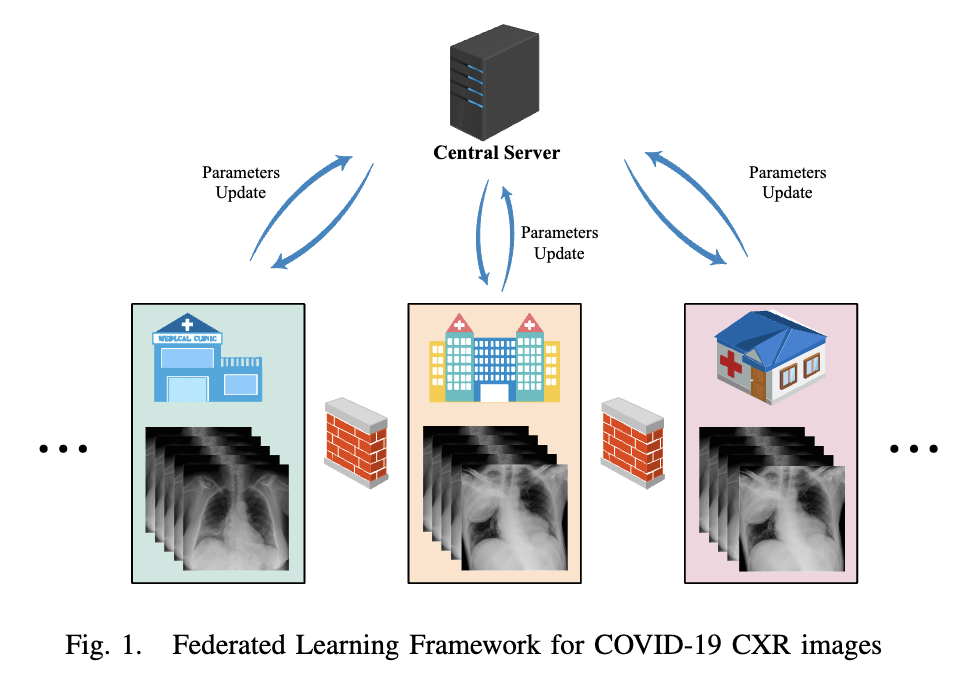
Experiments of Federated Learning for COVID-19 Chest X-ray Images
Bingjie YAN, Jun WANG, Jieren CHENG†, Yize ZHOU, Yixin ZHANG, Yifan YANG, Li LIU, Haojiang ZHAO, Chunjuan WANG, Boyi LIU († corresponding author )
ICAIS, EI (2021)
AI plays an important role in COVID-19 identification. Computer vision and deep learning techniques can assist in determining COVID-19 infection with Chest X-ray Images. However, for the protection and respect of the privacy of patients, the hospital's specific medical-related data did not allow leakage and sharing without permission. Collecting such training data was a major challenge. To a certain extent, this has caused a lack of sufficient data samples when performing deep learning approaches to detect COVID-19. Federated Learning is an available way to address this issue. It can effectively address the issue of data silos and get a shared model without obtaining local data. In the work, we propose the use of federated learning for COVID-19 data training and deploy experiments to verify the effectiveness. And we also compare performances of four popular models (MobileNet, ResNet18, MoblieNet, and COVID-Net) with the federated learning framework and without the framework. This work aims to inspire more researches on federated learning about COVID-19.
Experiments of Federated Learning for COVID-19 Chest X-ray Images
Bingjie YAN, Jun WANG, Jieren CHENG†, Yize ZHOU, Yixin ZHANG, Yifan YANG, Li LIU, Haojiang ZHAO, Chunjuan WANG, Boyi LIU († corresponding author )
ICAIS, EI (2021)
AI plays an important role in COVID-19 identification. Computer vision and deep learning techniques can assist in determining COVID-19 infection with Chest X-ray Images. However, for the protection and respect of the privacy of patients, the hospital's specific medical-related data did not allow leakage and sharing without permission. Collecting such training data was a major challenge. To a certain extent, this has caused a lack of sufficient data samples when performing deep learning approaches to detect COVID-19. Federated Learning is an available way to address this issue. It can effectively address the issue of data silos and get a shared model without obtaining local data. In the work, we propose the use of federated learning for COVID-19 data training and deploy experiments to verify the effectiveness. And we also compare performances of four popular models (MobileNet, ResNet18, MoblieNet, and COVID-Net) with the federated learning framework and without the framework. This work aims to inspire more researches on federated learning about COVID-19.
2020
An Improved Method for the Fitting and Prediction of the Number of COVID-19 Confirmed Cases Based on LSTM
Bingjie YAN, Jun WANG, Zhen ZHANG, Xiangyan TANG†, Yize ZHOU, Guopeng ZHENG, Qi ZOU, Yao LU, Boyi LIU, Wenxuan TU, Neal XIONG († corresponding author )
Computers, Materials and Continua, SCI (2020)
An Improved Method for the Fitting and Prediction of the Number of COVID-19 Confirmed Cases Based on LSTM
Bingjie YAN, Jun WANG, Zhen ZHANG, Xiangyan TANG†, Yize ZHOU, Guopeng ZHENG, Qi ZOU, Yao LU, Boyi LIU, Wenxuan TU, Neal XIONG († corresponding author )
Computers, Materials and Continua, SCI (2020)